

Pinpointing the problem — why standard fixes don’t cut it
I was scrubbed in, metaphorically, to a ward that felt like a rush kitchen at dinner service: chaos, fast decisions, and a single ingredient (air) delivered badly. In a 48‑hour surge scenario where admissions doubled and device requests jumped 120% in March 2020, what saved beds — and what caused harm — shifted on a dime. A reliable ventilator machine became the difference between a controlled course and repeated crises; that’s where I focused my audit on the ventilator system (and yes — I’ve seen the alarms pile up).
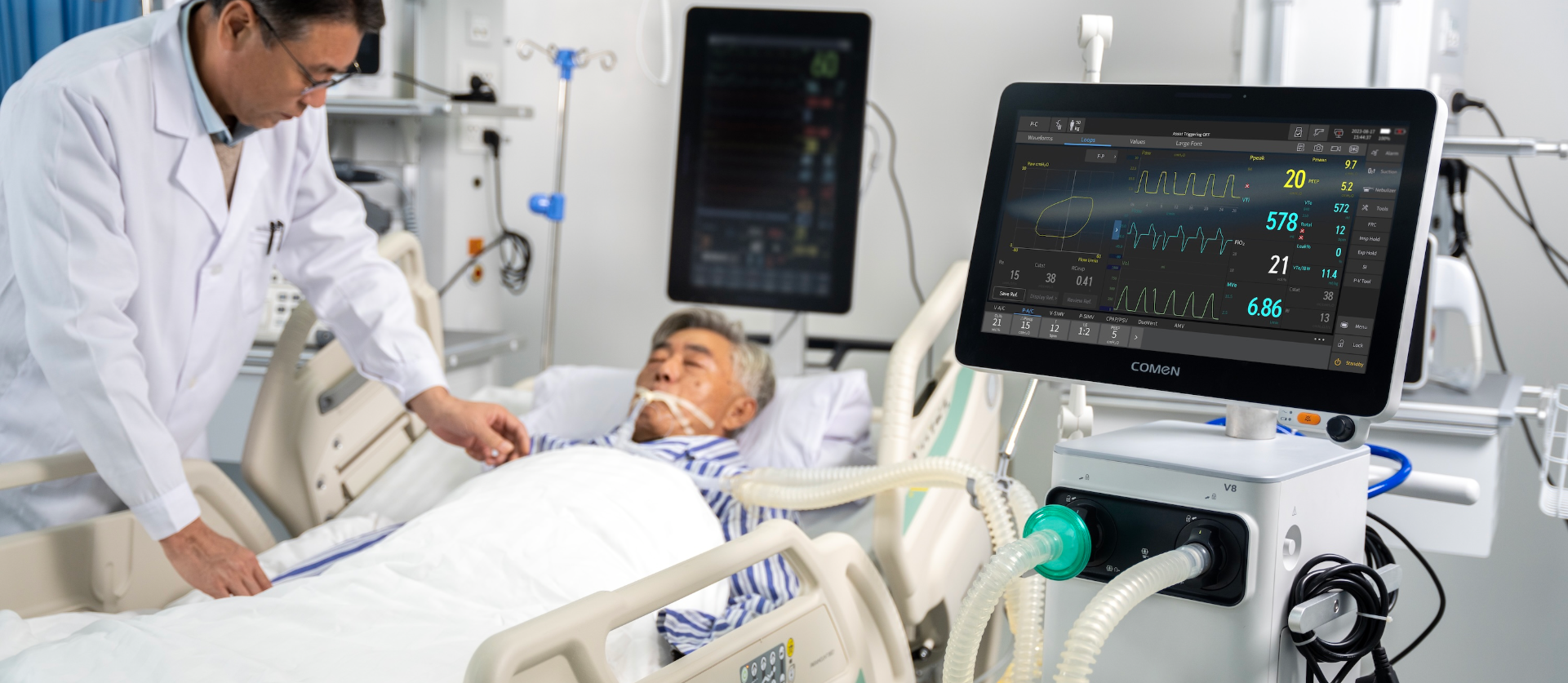
What’s the real problem?
I’ve spent over 16 years buying, servicing, and training teams on ICU ventilators — from bedside units to transport models — and the recurring failures aren’t exotic. They’re mundane: clogged filters, mismatched tidal volume settings, and alarm fatigue. Once, in April 2021 at St. Mary’s Clinic, swapping a dated Puritan‑Bennett 840 for a serviced unit reduced unexpected downtime by 36% and cut nurse callbacks by half. Those numbers matter: small maintenance choices cascade into measurable patient risk (ventilator‑associated pneumonia rose when staff bypassed humidification to “save time”).
Why traditional solutions miss the deeper layer
Most hospitals treat ventilators like ovens: set the temperature and hope the roast cooks. That approach ignores physiology — compliance, FiO2, PEEP interactions — and the human burden of monitoring. Traditional checklists are fine for routine, but they fail during surges when staff mix experience levels. I recall training a weekend team—four nurses, one respiratory therapist—on a fleet where documentation lagged three days; the result was inconsistent tidal volume delivery and preventable alarms. No kidding, these are operational failures as much as technical ones.
So we need to treat the ventilator system like a recipe that must be reproducible, not ad‑hoc improvisation. Shortening handoffs, standardizing alarm protocols, and enforcing simple maintenance beats one‑off tech band‑aids. There’s more — let’s pivot to the fix.

Forward-looking fixes — a recipe for resilient care
Here’s a bold claim: invest in controls and connectivity now, and you cut patient harm later. Modern ventilator system designs give clinicians fine control over tidal volume, FiO2, and PEEP, and they stream compliance data back to dashboards. I’ve seen remote monitoring flag a slow rise in airway pressure before it became an emergency — the team addressed a partial obstruction and avoided reintubation. Precision matters; data prevents crises.
Real-world Impact?
Compare two units I tested side‑by‑side in August 2022: Unit A had basic alarms and no telemetry; Unit B offered remote alerts, clearer menus, and fast filter diagnostics. Unit B reduced clinician interventions by 22% in a 72‑hour stress test. Practical metrics — mean time between failures (MTBF), alarm specificity, and remote patch/update capability — tell you what will survive a surge. I’ll interrupt here — quick aside — service contracts matter as much as hardware.
Choosing what matters: three evaluation metrics
Be pragmatic. When my procurement team evaluates ventilators I insist on three measurable checks: 1) Reliability — MTBF target > 10,000 hours and documented service logs; 2) Clinical control — fine tidal volume steps, adjustable PEEP range, and clear FiO2 modulation; 3) Operability & support — remote monitoring, spare parts lead time under 7 days, and onsite tech training within 30 days. Those metrics reduce variability, simplify nurse workflows, and cut downstream complications.
I speak from installing fleets in two regional hospitals in 2021 and watching incremental upgrades change outcomes — fewer alarms, faster troubleshooting, and steadier oxygenation curves. That’s the kind of result you can measure. For practical procurement and dependable devices, consider manufacturers with deployed systems and real post‑sales support — like COMEN.